Last Updated: May 2026
A delayed notification is any user-facing message that gets sent later than the event that triggered it: a 15-minute meeting reminder, a 24-hour cart abandonment email, a 3-day onboarding nudge, a 9 AM local-time digest. The naive answer is "use cron." The honest answer is that cron alone breaks the moment you care about timezones, crash recovery, duplicate suppression, or dynamic delay durations.
This guide walks through what counts as a delayed notification, the failure modes that bite engineering teams in production, the four implementation patterns that actually work, and where each pattern fits. It also covers timezone and DST handling, idempotency, and observability, the parts most tutorials skip.
What Counts as a Delayed Notification
A delayed notification is a notification scheduled to fire at a specific future time, not immediately when the triggering event occurs. The trigger and the delivery are decoupled.
Four shapes of delay show up in real products:
- Fixed delay from trigger: "Send a reminder 24 hours after signup if the user has not verified email."
- Dynamic delay derived from payload: "Send an alert 15 minutes before the scheduled appointment time, which varies per user."
- Conditional delay (wait-until-or-timeout): "Wait up to 30 minutes for the payment-completed event. If it does not arrive, send a payment-failed nudge."
- Recurring delay: "Send a weekly digest every Monday at 9 AM in the recipient's local timezone."
The opposite is an instant notification: a Slack DM, an OTP, a low-stock alert. Trigger fires, message goes out. Those are easy. The four shapes above are not, because each requires durable state, accurate clocks, and recovery from failure.
Why Cron Alone Falls Apart at Scale
A single cron job that polls a database every minute and dispatches pending notifications works fine for a side project. Five things start to crack as load and complexity grow.
1. Timezone and DST drift
A "9 AM digest" stored as UTC is wrong twice a year for every user observing daylight saving time. Storing the IANA timezone identifier (e.g., America/New_York) with the user, then recomputing the next fire time at evaluation, is the only correct approach. UTC offsets are not enough because they do not encode DST rules. The IANA Time Zone Database is the authoritative source most languages bind to.
2. Crash recovery
If the cron worker crashes at 8:59 AM and restarts at 9:01 AM, the 9 AM batch is either lost or fired late without acknowledgment. Durable storage of pending notifications plus an "at-least-once" delivery contract is required. That means every notification needs a persisted state row, not just a memory queue.
3. Duplicate delivery
Two cron workers running on two boxes will both pick up the same row unless you have row-level locking, SELECT FOR UPDATE SKIP LOCKED, or an external coordination layer (Redis, Zookeeper). At-least-once delivery without idempotency keys means users get the same notification twice. Idempotency keys at the recipient layer (channel-specific message IDs) suppress these.
4. Thundering herd
If a million users are all scheduled for 9 AM, you cannot fire a million HTTP requests to your email vendor in the same second. Per-second rate limits on SendGrid, Twilio, and FCM will return 429 Too Many Requests. You need either client-side smoothing (jittered delivery within a window) or per-vendor concurrency limits enforced before dispatch.
5. Dynamic delays
Cron expressions are static. They cannot express "remind me 15 minutes before the appointment_time field on this specific user's payload." Dynamic delays require a per-row "fire_at" timestamp, not a cron expression. That is a different storage model.
None of these problems are exotic. They show up the first time a delayed notification ships to more than a few thousand users.
Four Patterns Engineers Actually Use
The implementation choices boil down to four patterns. The tradeoffs:
| Pattern | Best For | Strengths | Weaknesses |
|---|---|---|---|
| Cron + DB polling | Low scale, simple cases | Easy to reason about, no infra | Polling overhead, race conditions, no sub-minute precision |
| Delay queues (SQS, Redis ZSET) | Mid-to-high scale, durable delays up to 15 min (SQS) or unbounded (Redis) | Durable, scales horizontally, no polling | SQS capped at 15 min; Redis needs you to run it |
| Job schedulers (BullMQ, Sidekiq, Quartz) | Application-level scheduling tied to a framework | Mature, rich tooling, dashboards | Tied to one language/runtime, harder to coordinate cross-service |
| Hashed timing wheels | Very high throughput, in-memory | O(1) insert, microsecond precision | Volatile (memory only), complex to operate |
Pattern 1: Cron + database polling
The simplest model. Store each pending notification with a fire_at timestamp. A cron job runs every minute, selects rows where fire_at <= now() and status = 'pending', marks them in_progress, dispatches, then marks sent.
import psycopg2
def claim_batch(batch_size=500):
"""Atomically claim a batch of due notifications. Returns rows to dispatch."""
with psycopg2.connect(DATABASE_URL) as conn:
with conn.cursor() as cur:
cur.execute("""
UPDATE scheduled_notifications
SET status = 'in_progress', claimed_at = NOW()
WHERE id IN (
SELECT id FROM scheduled_notifications
WHERE fire_at <= NOW() AND status = 'pending'
ORDER BY fire_at
LIMIT %s
FOR UPDATE SKIP LOCKED
)
RETURNING id, recipient_id, payload
""", (batch_size,))
return cur.fetchall()
def mark_sent(notif_id):
with psycopg2.connect(DATABASE_URL) as conn:
with conn.cursor() as cur:
cur.execute(
"UPDATE scheduled_notifications SET status='sent', sent_at=NOW() WHERE id=%s",
(notif_id,)
)
def process_due_notifications():
for notif_id, recipient_id, payload in claim_batch():
# Dispatch outside the claim transaction so row locks
# are released before slow network calls
dispatch(recipient_id, payload, idempotency_key=str(notif_id))
mark_sent(notif_id)
Three non-obvious details. First, FOR UPDATE SKIP LOCKED (PostgreSQL 9.5+) is what prevents two workers from grabbing the same row, this clause was added specifically for queue-like workloads. Second, the claim and the dispatch live in separate transactions, claiming holds a brief row lock, the actual vendor HTTP call happens after the lock is released. Holding row locks across slow network calls is a common production bug. Third, notif_id passes downstream as the idempotency key so a retry does not fire the message twice. One gap to handle in production: if dispatch() raises an exception before mark_sent() runs, the row stays in_progress indefinitely. Add a cleanup job that resets rows stuck in in_progress beyond a threshold (e.g., 10 minutes) back to pending.
Limits: every-minute polling means a notification scheduled for 9:00:30 will not fire until 9:01:00. Polling 500 rows at a time on a table with millions of pending rows pressures the index. This pattern caps out around tens of thousands of pending delays before you need to move to a queue.
Pattern 2: Delay queues (SQS, Redis sorted sets)
A delay queue accepts a message with an "available at" time and returns it to consumers only after that time has passed. No polling on your end; the queue handles the timing.
AWS SQS supports per-message delays up to 15 minutes via the DelaySeconds parameter. For delays longer than 15 minutes, combine SQS with EventBridge Scheduler (one-off at any future time).
import boto3
import json
sqs = boto3.client("sqs")
def schedule_short_delay(queue_url, recipient_id, payload, delay_seconds):
if delay_seconds > 900:
raise ValueError("SQS DelaySeconds maximum is 900 (15 minutes)")
sqs.send_message(
QueueUrl=queue_url,
MessageBody=json.dumps({
"recipient_id": recipient_id,
"payload": payload,
}),
DelaySeconds=delay_seconds,
MessageDeduplicationId=f"{recipient_id}:{payload['template']}",
)
For arbitrary delay durations, a Redis sorted set is the standard pattern. Score each entry by its Unix-epoch fire timestamp, then have a worker periodically pop entries whose score is less than or equal to the current time.
import redis
import time
import json
r = redis.Redis()
SCHEDULE_KEY = "notifications:scheduled"
# Atomic claim: read up to N due members AND remove only those exact members.
# A pipeline is NOT enough here, two workers could both read the same members
# before either removes them. A Lua script runs atomically inside Redis.
CLAIM_LUA = """
local due = redis.call('ZRANGEBYSCORE', KEYS[1], 0, ARGV[1], 'LIMIT', 0, ARGV[2])
if #due > 0 then
redis.call('ZREM', KEYS[1], unpack(due))
end
return due
"""
claim_due = r.register_script(CLAIM_LUA)
def schedule(recipient_id, payload, fire_at_epoch):
member = json.dumps({
"recipient_id": recipient_id,
"payload": payload,
"id": payload["id"], # stable idempotency key
})
r.zadd(SCHEDULE_KEY, {member: fire_at_epoch})
def drain_due(batch_size=200):
members = claim_due(keys=[SCHEDULE_KEY], args=[time.time(), batch_size])
for raw in members:
entry = json.loads(raw)
dispatch(entry["recipient_id"], entry["payload"], idempotency_key=entry["id"])
The Lua script matters. The naive version, calling ZRANGEBYSCORE with a limit then ZREMRANGEBYSCORE over the same range, has a silent data-loss bug: the range-remove deletes all due entries while the range-read returned only batch_size. A pipeline does not help because pipelined commands are batched for network efficiency but are not executed atomically (per the Redis docs). The Lua script reads N members and removes exactly those N inside a single Redis-side execution.
The ZADD + claim sequence is O(log N) for insert and O(log N + M) for drain, where M is the batch size. A single Redis instance comfortably holds tens of millions of pending entries. For higher volume, shard the schedule into K keys (e.g., notifications:scheduled:{user_id % K}) so each ZSET lives on a single Cluster slot and the work parallelizes across slots. For more on Redis-backed schedulers, see scaling a notification service with Python and Redis.
Pattern 3: Job schedulers (BullMQ, Sidekiq, Quartz)
If you already run a job queue for background work, most of them support delayed jobs out of the box. BullMQ (Node.js, Redis-backed), Sidekiq (Ruby), and Quartz (Java) are the common ones.
import { Queue } from "bullmq";
const notificationsQueue = new Queue("notifications", {
connection: { host: "localhost", port: 6379 },
});
async function scheduleNotification(
recipientId: string,
payload: Record<string, unknown>,
delayMs: number
) {
await notificationsQueue.add(
"send-notification",
{ recipientId, payload },
{
delay: delayMs,
jobId: `${recipientId}:${payload.templateId}`, // idempotency
removeOnComplete: true,
attempts: 5,
backoff: { type: "exponential", delay: 2000 },
}
);
}
This pattern gets you retries, exponential backoff, dashboards (BullMQ has Bull Board via @bull-board/api) and metrics for free. The tradeoff is coupling: BullMQ jobs are tied to your Node runtime. If your dispatch logic moves to a different service, you have to rewrite the worker.
Pattern 4: Hashed timing wheels
Used inside high-throughput systems (Netty's HashedWheelTimer, Kafka's request purgatory, some database internals) for low-latency delay scheduling at hundreds of thousands of inserts per second. The data structure is a circular array of buckets indexed by (fire_time / tick_duration) mod bucket_count, with O(1) insertion and O(1) tick. It is overkill for almost every notification use case. The reason to know it exists is to recognize when "we need delayed notifications" actually means "we need a delay queue" and not "we need to roll our own timing wheel."
The Pitfalls Nobody Documents
Idempotency keys
Every retry path (queue redelivery, worker crash, retry on vendor 5xx) can fire the same notification twice. The fix is a stable identifier (e.g., "notif:<notification_id>") attached to every dispatch attempt. Some vendor APIs expose this directly (Stripe-style Idempotency-Key headers); others require you to deduplicate at your own boundary before calling the vendor. SuprSend exposes idempotency_key on every workflow trigger so the platform handles dedupe before any vendor call.
Clock skew across workers
If worker A's clock is 30 seconds ahead of worker B's, "fire at 9:00:00" means worker A fires at 8:59:30. Use NTP on every node, or in AWS use the Amazon Time Sync Service which keeps EC2 within ~1ms of UTC. For delays measured in minutes or hours, residual skew is noise. For sub-second precision (high-frequency trading alerts, real-time games), clock skew between workers becomes material and you should either pin scheduling to a single coordinator or use logical clocks.
Cancellation
If a user unsubscribes 12 hours before a scheduled email fires, the email should not send. Cancellation requires either a "tombstone" lookup at dispatch time (check status before sending) or a way to delete the pending notification from the queue. Redis ZSETs support ZREM. SQS does not support deletion of pending delayed messages in practice - while SQS has a DeleteMessage API, it requires a receipt handle, which is only issued when the message becomes visible to a consumer. Messages still within their delay window have not surfaced yet, so there is no receipt handle to delete them. Decide your cancellation policy before picking storage.
Observability
"Why did this user not get their notification?" is the single most common notification bug, and it is unanswerable without per-notification logs. At minimum, log: scheduled time, fire time, dispatch time, vendor response, vendor message ID, idempotency key. Per-notification observability is one of the hardest things to add after the fact. See notification observability for a deeper treatment.
Retry on failed delivery
A scheduled notification that fires on time but fails at the vendor (Twilio returns 500, FCM rejects a stale token) needs a separate retry policy from the scheduling logic. Conflating "the delay" with "the delivery retry" produces hard-to-debug behavior. Keep them as two distinct concerns.
Recurring and Conditional Delays
The four patterns above handle one-shot delays. Two adjacent use cases need slightly different handling.
Recurring notifications
"Send a weekly digest every Monday at 9 AM in the user's timezone." Two approaches:
- Materialize the next occurrence: When a delay fires, immediately schedule the next one. The queue only ever holds one pending row per user per schedule.
- Cron-based fan-out: A meta-cron runs at the start of every minute, finds all users whose local time is currently 9 AM Monday, and enqueues their digest. Scales better for fixed schedules; harder when each user has a custom recurrence.
For most product use cases the "materialize the next occurrence" approach is simpler. The hard part is recomputing the next fire time in the user's IANA timezone, which Python's zoneinfo and Node's luxon handle correctly. Avoid hand-rolling timezone math.
Conditional delays (wait-until-or-timeout)
"Wait up to 30 minutes for the payment-completed event. If it does not arrive, send a payment-failed nudge." This is not a pure delay; it is a race between an event and a timer.
The clean model: a workflow state machine with two transition rules. (1) on event arrival, cancel the timer and proceed down the success branch. (2) on timer expiry, proceed down the timeout branch. Each entry needs durable state because the wait can outlive worker restarts.
Implementing this from scratch is non-trivial. It is also one of the most-used patterns in real product flows: cart abandonment, payment retries, OTP timeout, two-factor fallback. SuprSend's Wait Until node is built for exactly this shape.
Timezone, DST, and Quiet Hours
Three rules that save weeks of debugging.
Store IANA identifiers, not offsets. A user in New York is America/New_York, not UTC-5. The offset changes twice a year. The identifier encodes the DST rules.
Recompute fire times at the moment of evaluation, not at the moment of scheduling. If a user changes timezone between scheduling and firing, the original UTC fire time will be wrong. Store the local-time intent ("9 AM in user's tz") and the IANA identifier separately. Compute UTC fire time at dispatch.
Respect channel-specific quiet hour rules. US SMS marketing messages must comply with TCPA (47 CFR § 64.1200), which restricts delivery to between 8 AM and 9 PM in the recipient's local time. A delayed SMS scheduled at 2 AM local violates that even if the original trigger was at noon. Quiet-hours enforcement at dispatch time, not just schedule time, is what keeps you compliant.
SuprSend's Time Window node handles all three: IANA identifiers, DST-aware recomputation, recurring windows with quiet-hour exclusion.
Where SuprSend Fits
The four implementation patterns above all work. They also represent six to twelve months of engineering investment if you build production-grade versions of each, plus ongoing operational cost. The build-vs-buy math is covered in build vs buy for notification service.
One emerging use case worth flagging: AI agents triggering delayed notifications. As teams build autonomous agents with tools like LangChain, CrewAI, or Mastra, those agents increasingly need to schedule follow-up messages - "remind this user 24 hours after the agent completes a task" or "send an escalation if no response arrives within 6 hours." SuprSend's MCP Server exposes workflow triggers as native tools that any AI agent can call, which means the delay and wait-until logic described above is available to agents without any custom scheduler code.
SuprSend exposes four primitives that map onto the patterns above:
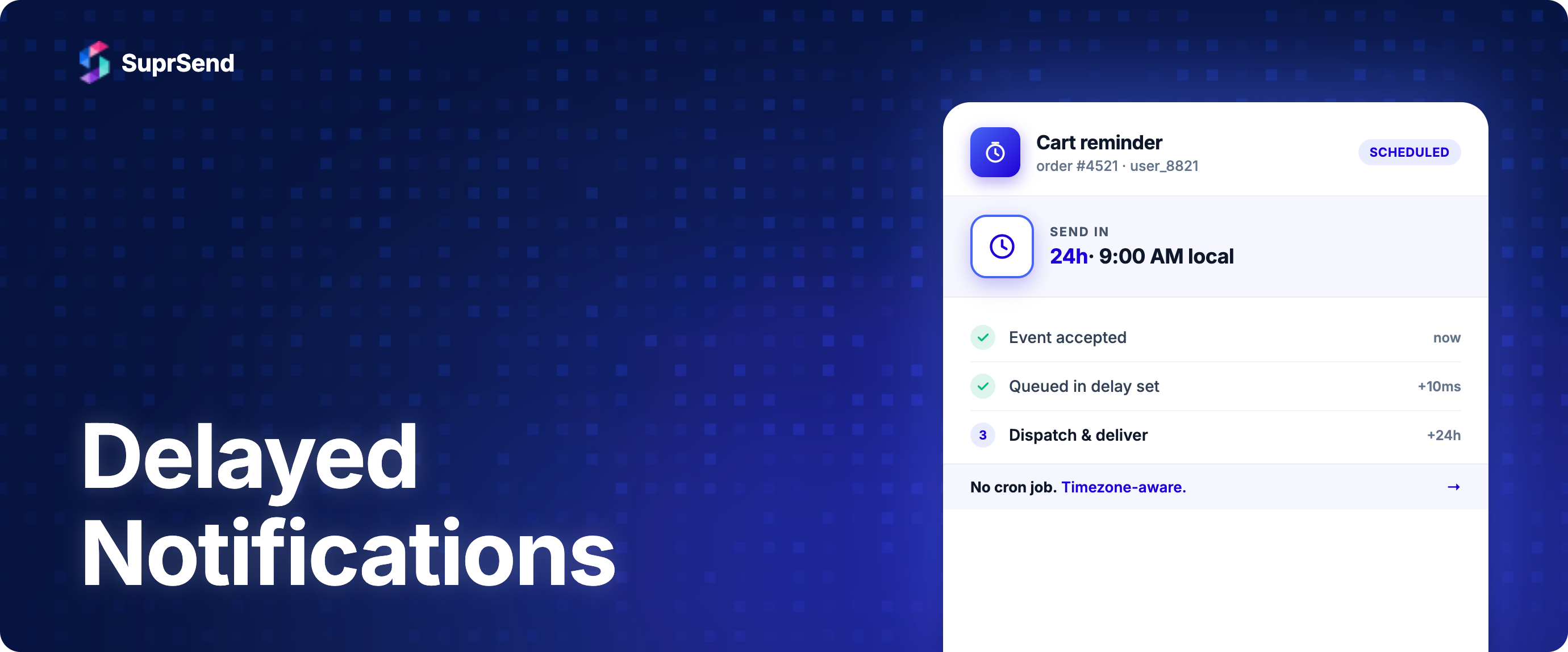
- Delay node: Fixed, dynamic (JQ expression on payload), or relative-to-future-timestamp pause. Format
2d 5h 30m, ISO-8601 timestamps, or integer seconds. - Wait Until node: Pauses until either an event-based condition is satisfied or the max wait expires. Handles the cart-abandonment / payment-retry race pattern natively.
- Time Window node: Recipient-timezone-aware delivery windows. IANA identifiers, DST handling, recurring schedules (daily, weekdays, specific weekdays). Useful for quiet hours and TCPA windows.
- Broadcast: Bulk scheduled sends to a user list. Three modes: immediate, after-delay (relative to click), or absolute scheduled datetime.
A fifth layer sits above these four primitives: send-time optimization. Choosing a fixed delay like "24 hours after signup" works at average. What works better is letting the platform learn when each specific user is most likely to open a message based on their past engagement and adjust the fire time accordingly. Static delays are the floor; per-user optimal delivery time is the ceiling. This is where notification infrastructure moves from scheduling to intelligence.
A workflow with all four configured looks like this from the SDK side. The Delay node configuration lives on the workflow definition; the SDK trigger just passes data.
from suprsend import Suprsend, WorkflowTriggerRequest
supr_client = Suprsend("WORKSPACE_KEY", "WORKSPACE_SECRET")
w1 = WorkflowTriggerRequest(
body={
"workflow": "appointment_reminder",
"recipients": [
{
"distinct_id": "user_8f3a",
"$email": ["jane.doe@example.com"],
"$timezone": "America/Los_Angeles",
}
],
"data": {
"appointment_time": "2026-06-12T15:00:00Z",
"reminder_lead_minutes": 15,
},
},
idempotency_key="appt_reminder_8f3a_2026-06-12",
)
response = supr_client.workflows.trigger(w1)
The workflow itself, configured in the dashboard, references $.data.appointment_time on a relative Delay node with a 15-minute lead. The Time Window node enforces TCPA hours. The Wait Until node listens for an appointment_cancelled event and aborts the workflow if it fires before delivery.
What this saves: the DB schema, the polling worker, the timezone math, the idempotency layer, the per-channel rate limiting, the cancellation logic, the observability layer. All four patterns above, abstracted into nodes that product teams can wire up without writing scheduler code.
For a fuller picture of how the workflow engine handles these primitives, see notification workflow engine. For the architectural reasons centralized notification infrastructure beats one-off cron jobs, see why building notifications is so hard.
FAQ
What is the difference between a delayed notification and a scheduled notification?
They overlap heavily. "Delayed" usually means a relative offset from a trigger ("send 30 minutes later"). "Scheduled" usually means an absolute future time ("send at 9 AM Monday"). The same delay-queue infrastructure handles both, the only difference is whether you compute fire_at = now() + offset or fire_at = explicit_timestamp.
Can I use cron for delayed notifications?
For small scale, yes. Once you have more than a few thousand pending delays, more than one worker process, or any timezone requirement, cron alone is insufficient. You need at minimum a durable store with per-row fire times plus row-level locking (FOR UPDATE SKIP LOCKED) to prevent duplicate dispatch.
How do I cancel a delayed notification before it fires?
Depends on the backing store. Redis ZSETs support ZREM by member. Database rows support UPDATE SET status='cancelled'. AWS SQS does not support deletion of pending delayed messages, so cancellation requires a tombstone-check at dispatch time. Choose your store based on cancellation requirements.
How do I prevent duplicate delayed notifications?
Two layers. First, at-most-once enqueue: deduplicate on a stable key (e.g., {user_id}:{template_id}:{date}) so the same logical notification cannot be scheduled twice. Second, at-most-once dispatch: pass an idempotency key to the downstream vendor so a retried dispatch does not send twice.
How do delayed notifications work across timezones?
Store the user's IANA timezone identifier (America/New_York, not UTC-5). Store the local-time intent ("9 AM Monday") separately from any UTC representation. Recompute the next fire time at evaluation, not at scheduling, so timezone changes and DST transitions are handled correctly.
What is the maximum delay SQS supports?
AWS SQS DelaySeconds maxes out at 900 seconds (15 minutes). For delays longer than 15 minutes, combine SQS with EventBridge Scheduler, use a Redis sorted set, or use a database-backed scheduler.
Can I run a delayed notification system on serverless?
Yes. EventBridge Scheduler + Lambda is the standard AWS pattern. Each scheduled rule is a one-shot Lambda invocation at the target time. The tradeoff is per-rule cost at very high scale: at one million scheduled notifications, the rule count gets expensive. A Redis ZSET + ECS worker is cheaper above a few hundred thousand pending entries.
How do I handle a notification that fires successfully but the user has changed preferences?
Check preferences at dispatch time, not at schedule time. The fire-at evaluator should hit your preference store (or the user-properties table) and skip-or-route based on current state. Scheduling a notification 24 hours in advance based on a preference that is stale by the time it fires is a common bug.
TL;DR
Delayed notifications are notifications scheduled to fire at a specific future time rather than immediately. Cron alone fails at production scale because of timezone drift, crash recovery, duplicate dispatch, thundering herds at fixed times, and the impossibility of expressing dynamic per-row delays. The four working patterns are: cron + database polling (small scale), delay queues like SQS or Redis sorted sets (mid-to-high scale), job schedulers like BullMQ or Sidekiq (framework-coupled), and hashed timing wheels (high-throughput specialized). Beyond the storage choice, the operational pitfalls are idempotency, clock skew, cancellation, observability, and DST. SuprSend's Delay, Wait Until, Time Window, and Broadcast primitives implement these patterns so product teams do not have to rebuild them.
Next Steps
If you are evaluating whether to build or buy notification delay infrastructure, the simplest path is to start building for free on SuprSend's free tier (10,000 notifications/month, all channels, no credit card) and wire up a Delay node in under 15 minutes. If you want to walk through your specific scheduling and recurring requirements with our team, book a demo.





